In a previous post, I detailed some of the features of MathOptSetDistances.jl and the evolution of the idea behind it. This is part II focusing on derivatives.
Table of Contents
The most interesting part of the packages is the projection onto a set. For some applications, what we need is not only the projection but also the derivative of this projection.
One answer here would be to let Automatic Differentiation (AD) do the work. However:
- Just like there are closed-form expressions for the projection, many sets admit closed-form projection derivatives that can be computed cheaply,
- Some projections may require to perform steps impossible or expensive with AD, as a root-finding procedure1 or an eigendecomposition2;
- Some functions might make calls into deeper water. JuMP for instance supports a lot of optimization solvers implemented in C and called as shared libraries. AD will not propagate through these calls.
For these reasons, AD systems often let users implement some derivatives themselves, but as a library developer, I do not want to depend on a full AD package (and force downstream users to do so).
Meet ChainRules.jl
ChainRules.jl is a Julia package addressing exactly the issue mentioned above: it defines a set of primitives to talk about derivatives in Julia. Library developers can implement custom derivatives for their own functions and types. Finally, AD library developers can leverage ChainRules.jl to obtain derivatives from functions when available, and otherwise use AD mechanisms to obtain them from more elementary functions.
The logic and motivation is explained in more details in Frame’s talk at JuliaCon 2020 and the package documentation which is very instructive on AD in general.
Projection derivative
We are interested in computing $D\Pi_{\mathcal{S}}(v)$, the derivative of the projection with respect to the initial point. As a refresher, if $\Pi_s(\cdot)$ is a function from $V$ onto itself, and if $V$ then the derivative $D\Pi$ maps a point in $V$ onto a linear map from the *tangent space* of $V$ onto itself. The tangent space of $V$ is roughly speaking the space where differences of values in $V$ live. If $V$ corresponds to real numbers, then the tangent space will also be real numbers, but if $V$ is a space of time/dates, then the tangent space is a duration/time period. See here3 for more references. Again, roughly speaking, this linear map takes perturbations of the input $\Delta v$ and maps them to perturbation of the projected point $\Delta v_p$.
As an example warm-up:
- $S$ is the whole domain of $v$ $\Rightarrow$ the projection is $v$ itself, $D\Pi_{\mathcal{S}}(v)$ is the identity operator.
- $S$ is $\{0\}^n$ $\Rightarrow$ the projection is always $\{0\}^n$, $D\Pi_{\mathcal{S}}(v)$ maps every $Δv$ to a zero vector: perturbations in the input do not change the output.
$D\Pi_{\mathcal{S}}(v)$ is a linear map from $\mathcal{V}$ to $\mathcal{V}$. If $v \in \mathbb{R}^n$, it can be represented as a $n\times n$ matrix. There are several ways of representing linear maps, see the LinearOperators.jl package for some insight. Two approaches (for now) are implemented for set distances:
- Matrix approach: given $v \in \mathbb{R}^n$, return the linear operator as an $n\times n$ matrix.
- Forward mode: given $v$ and a direction $\Delta v$, provide the directional derivative $D\Pi_{\mathcal{S}}(v) \Delta v$.
- Reverse mode: given $v$, provide a closure corresponding to the adjoint of the derivative.
(1) has been implemented by Akshay for many sets during his GSoC this summer, along with the projections themselves.
(1) corresponds to computing the derivative eagerly as a full matrix, thus
paying storage and computation cost upfront. The advantage is the simplicity for standard vectors,
take v, s, build and return the matrix.
(2) is the building block for forward-mode differentiation:
given a point $v$ and an input perturbation $\Delta v$, compute the output perturbation.
(3) corresponds to a building block for reverse-mode differentiation.
An aspect of the matrix approach is that it works well for 1-D arrays
but gets complex quite quickly for other structures, including multi-argument
functions or matrices. Concatenating everything into a vector is too rigid.
Example on the nonnegative orthant
The nonnegative orthant cone is the set $\mathbb{R}^n_+$; it is represented in MOI
as MOI.Nonnegatives(n) with n the dimension.
The projection is simple because it can be done elementwise:
$$
(\Pi_S(v))_i = max(v_i, 0) \,\,\forall i.
$$
In other terms, any non-diagonal term of the gradient matrix is 0 for any $v$. Here is a visualization made with haste for $n=2$ using the very promising Javis.jl:
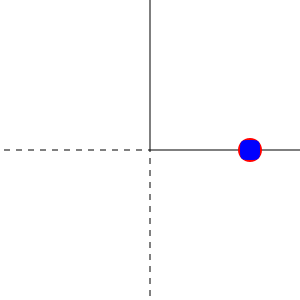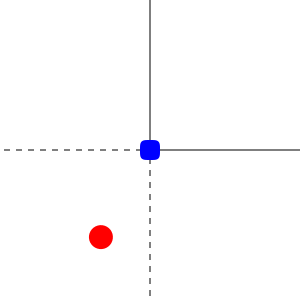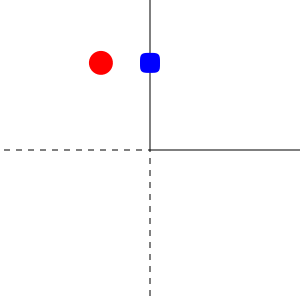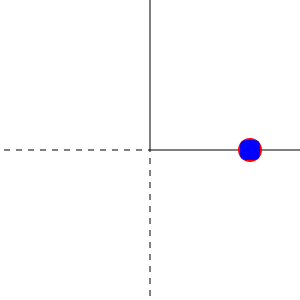
The red circle is a vector in the plane and the blue square its projection.4
The Julia implementation follows the same idea, here in a simplified version:
function projection_on_set(v::AbstractVector{T}, s::MOI.Nonnegatives) where {T}
return max.(v, zero(T))
end
For each component $i \in 1..n$, there are two cases to compute its derivative, either the constraint is active or not.
$$
\begin{align}
v_i < 0 & \Rightarrow \frac{\partial \Pi_i}{\partial v_i}(v) = 0\\
v_i > 0 & \Rightarrow \frac{\partial \Pi_i}{\partial v_i}(v) = 1.
\end{align}
$$
The projection is not differentiable on points where one of the components is 0. The convention usually taken is to return any quantity on such point (to the best of my knowledge, no system guarantees a subgradient). The Julia implementation holds on two lines:
function projection_gradient_on_set(v::AbstractVector{T}, ::MOI.Nonnegatives) where {T}
y = (sign.(v) .+ one(T)) / 2
return LinearAlgebra.Diagonal(y)
end
First the diagonal of the matrix is computed using broadcasting and the sign function.
Then a LinearAlgebra.Diagonal matrix is constructed. This matrix type is sparsity-aware,
in the sense that it encodes the information of having only non-zero entries on
the diagonal. We save on space, using $O(n)$ memory instead of $O(n^2)$ for a
full matrix, and can benefit from specialized methods down the line.
We implemented the matrix approach from scratch. Even though we materialize the derivative as a diagonal matrix, it still costs storage, which will become a burden when we compose this projection with other functions and compute derivatives on the composition.
Forward rule
For a function f, value v and tangent Δv, the forward rule, or frule
in ChainRules.jl does two things at once:
- Compute the function value
y = f(v), - Compute the directional derivative
∂y = Df(v) Δv.
The motivation for computing the two values at once is detailed in the
documentation.
Quite often, computing the derivative will require computing f(v) itself
so it is likely to be interesting to return it anyway instead of forcing the user
to call the function again.
The exact signature of ChainRulesCore.frule involves some details we want to
ignore for now, but the essence is as follows:
function frule((Δself, v...), ::typeof(f), v...; kwargs...)
...
return y, ∂y
end
∂Y is the directional derivative using the direction Δx. Note here the variadic
Δx and x, since we do not want to impose a rigid, single-argument structure
to functions. The Δself argument is out of scope for this post but you can read
on its use in the docs.
For our set projection, it may look like this:
function ChainRulesCore.frule(
(_, Δv, _),
::typeof(projection_on_set),
v::AbstractVector{T}, s::MOI.Nonnegatives) where {T}
vproj = projection_on_set(v, s)
∂vproj = Δv .* (v .>= 0)
return vproj, ∂vproj
end
The last computation line leverages broadcast to express elementwise the
multiplication of Δv with the indicator of v[i] being nonnegative.
The important thing to note here is that we never build the derivative as a data
structure. Instead, we implement it as a function. An equivalent using our
projection_gradient_on_set would be:
function projection_directional_derivative(v, Δv, s)
vproj = projection_on_set(v, s)
DΠ = projection_gradient_on_set(v, s)
∂vproj = DΠ * Δv
return vproj, ∂vproj
end
Notice the additional allocation and matrix-vector product.
Reverse rules
The forward mode is fairly intuitive, the backward mode less so. The motivation for using it, and the reason it is the favoured one for several important fields using AD, is that it can differentiate a composition of functions with only matrix-vector products, instead of requiring matrix-matrix products. What it computed is, given a perturbation in the output (or seed), provide the corresponding perturbation in the input. There are great resources online which will explain it in better terms than I could so we will leave it at that.
Looking at the rrule signature from ChainRules.jl:
function rrule(::typeof(f), x...; kwargs...)
y = f(x...)
function pullback_f(Δy)
# implement the pullback here
return ∂self, ∂x
end
return y, pullback_f
end
This is a bit denser. rrule takes the function as input and its arguments.
So far so good. It returns two things, the value y of the function, similalry to frule
and a pullback. This term comes from differential geometry and in the context
of AD, is also referred to as a backpropagator. Again, the ChainRules
docs
got your back with great explanations.
It also corresponds to the Jacobian-transpose vector product if you prefer the term.
In the body of pullback_f, we compute the variation of the output with respect to each input.
If we give the pullback a 1 or 1-like as input, we compute the gradient,
the partial derivative of f with respect to each input x[i] evaluated at the
point x.
Here is the result for our positive orthant (again, simplified for conciseness):
function ChainRulesCore.rrule(::typeof(projection_on_set), v, s::MOI.Nonnegatives)
vproj = projection_on_set(v, s)
function pullback(Δvproj)
n = length(v)
v̄ = zeros(eltype(Δvproj), n)
for i in 1:n
if vproj[i] == v[i]
v̄[i] = Δvproj[i]
end
end
return (ChainRulesCore.NO_FIELDS, v̄, ChainRulesCore.DoesNotExist())
end
return (vproj, pullback)
end
The first step is computing the projection, here we do not bother with saving
for loops and just call the projection function.
For each index i of the vector, if the i-th projection component is equal to
the i-th initial point, $v_i$ is in the positive orthant and variations of
the output are directly equal to variations of the input. Otherwise,
this means the non-negativity constraint is tight, the projection lies on
the boundary vproj[i] = 0, and output variations are not propagated to the input
since the partial derivative is zero.
We see here that a tuple of 3 elements is returned. The first corresponds to
∂self, out of the scope for this package. The second is the interesting one,
v̄, the derivative with respect to the input point.
The last one ChainRulesCore.DoesNotExist() indicates that there is no derivative
with respect to the last argument of projection_on_set, namely the set s.
This makes sense because there is nothing to differentiate in the set.
An interesting point to notice is that the implementation, not the types defines the derivatives.
A non-trivial example would be a floating-point argument p only used to extract
the sign bit. This means it would not have a notion of local perturbation.
The type (a floating-point) would be interpreted as differentiable.
To my understanding, Swift for Tensorflow uses
a type-first approach, where types indicate what field gets differentiated.
If you imagine using this in practice, in an AD library for instance,
one would first call rrule forward, computing primal values and collecting the
successive pullbacks. Once we arrive at the end of our chain of functions,
we could backpropagate from $\Delta Y_{final} = 1$, walking our way back to
the primary input parameters.
Conclusion
This post comes after a few weeks of work on MathOptSetDistances.jl, the package with the actual implementation of the presented features. There is still a lot to learn and do on the topic, including solutions to more projections and derivatives thereof, but also interesting things to build upon. Defining derivatives and projections is after all a foundation for greater things to happen.
Notes
-
See H. Friberg’s talk on exponential cone projection in Mosek at ISMP 2018 ↩︎
-
An example case for the projection onto the Positive Semidefinite cone ↩︎
-
If like me you haven’t spent much time lying around differential geometry books, the ChainRules.jl documentation has a great developer-oriented explanation. For more visual explanations, Keno Fischer had a recent talk on the topic. ↩︎